on
基于Mach-O的包体积优化实践
作者:蒋伟 网易云信客户端架构师
简介
移动互联网时代,App的功能越来越多,集成的第三方库也与日俱增,然而苹果App使用4G能够下载的限制虽然已经提到高200MB,依然对于App开发者显得捉襟见肘。因此App开发者都带着谨慎的态度去集成第三方SDK供应商。 网易云信音视频服务的主要产品形态包含iOS/Android SDK,我们深刻的感受到包体积优化的重要性,因此包体积优化就成了我们工作的重中之重。 如何优化体积到极致,超越竞争对手,就成了我们不得不深入研究的课题。
本文旨在分享一个网易云信基于Mach-O研究思路的瘦身最佳实践成果。
常见的App瘦身技巧
- 精简资源(我们SDK没图片资源,故跳过)
- 优化可执行文件
Optimization Level: Fastest,Smallest Deployment Postprocessing: Yes Strip linked Product: Yes Symbols Hidden by default: Yes Strip Debug Symbols During Copy: Yes Make String Read-Only: Yes这些耳熟能详的默认配置我们都要打开。
在这些都打开了之后的基础之上,我们还有进一步压榨的空间。在此之前,我们首先要讲一下Mach-O格式。
Mach-O格式
Mach-O 其实是 Mach Object 文件格式的缩写,是 mac 以及 iOS 上可执行文件的格式。
它是一种用于可执行文件、目标代码、动态库的文件格式。
属于 Mach-O 格式的常见文件:
.o 目标文件
.a 静态库文件
.dylib 动态库文件
.framework 动态/静态框架库
.app 可执行文件
.dsym ( 符号表 )
可以查看此类格式文件的工具有:
Mach-O Viewer: https://sourceforge.net/projects/machoview/
Mach-O Explorer: https://github.com/DeVaukz/MachO-Explorer
常用的命令行有:
nm NERtcSDK.framework/NERtcSDK // 打印所有symbol
lipo -info NERtcSDK.framework/NERtcSDK
Architectures in the fat file: NERtcSDK.framework/NERtcSDK are: i386 x86_64 armv7 arm64
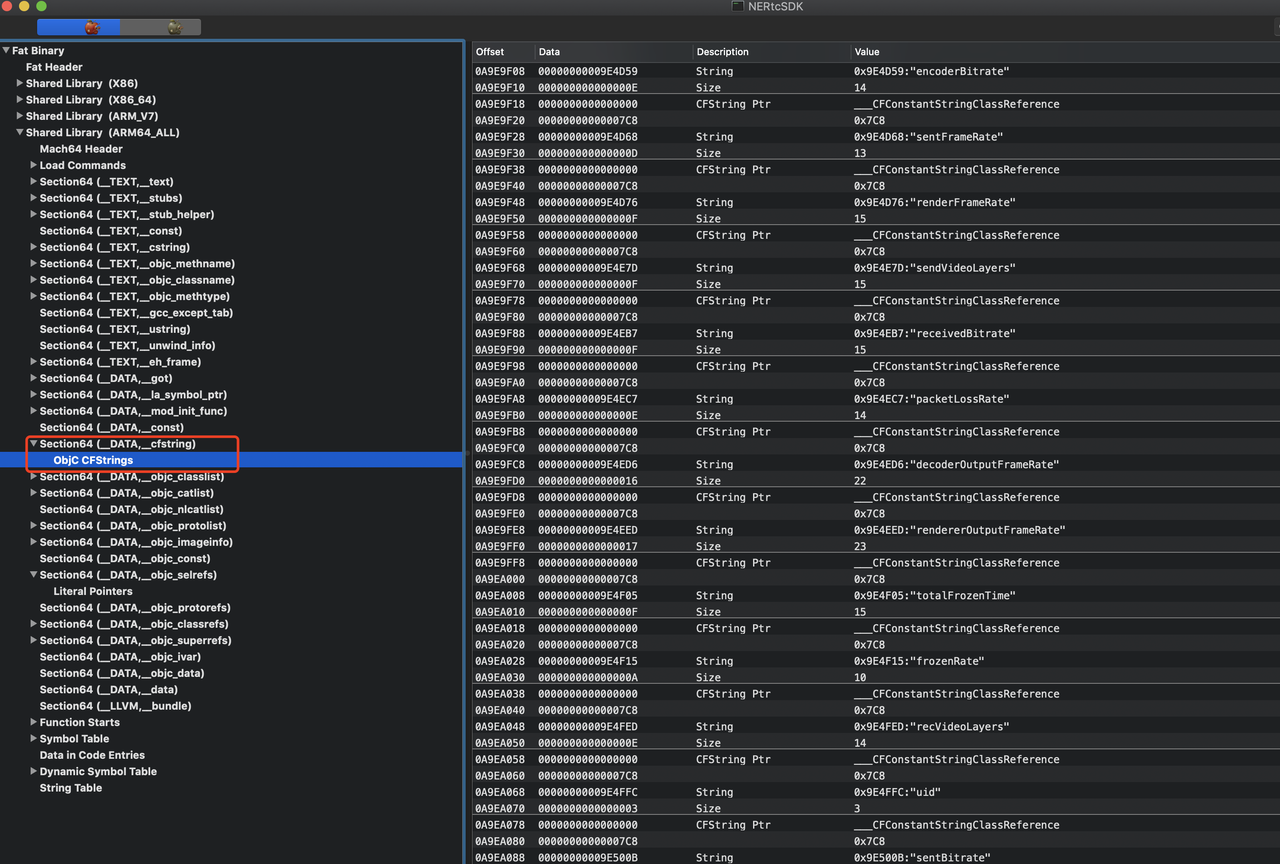
先贴上我们的SDK打开后的样式,我们一起来试着读一读:
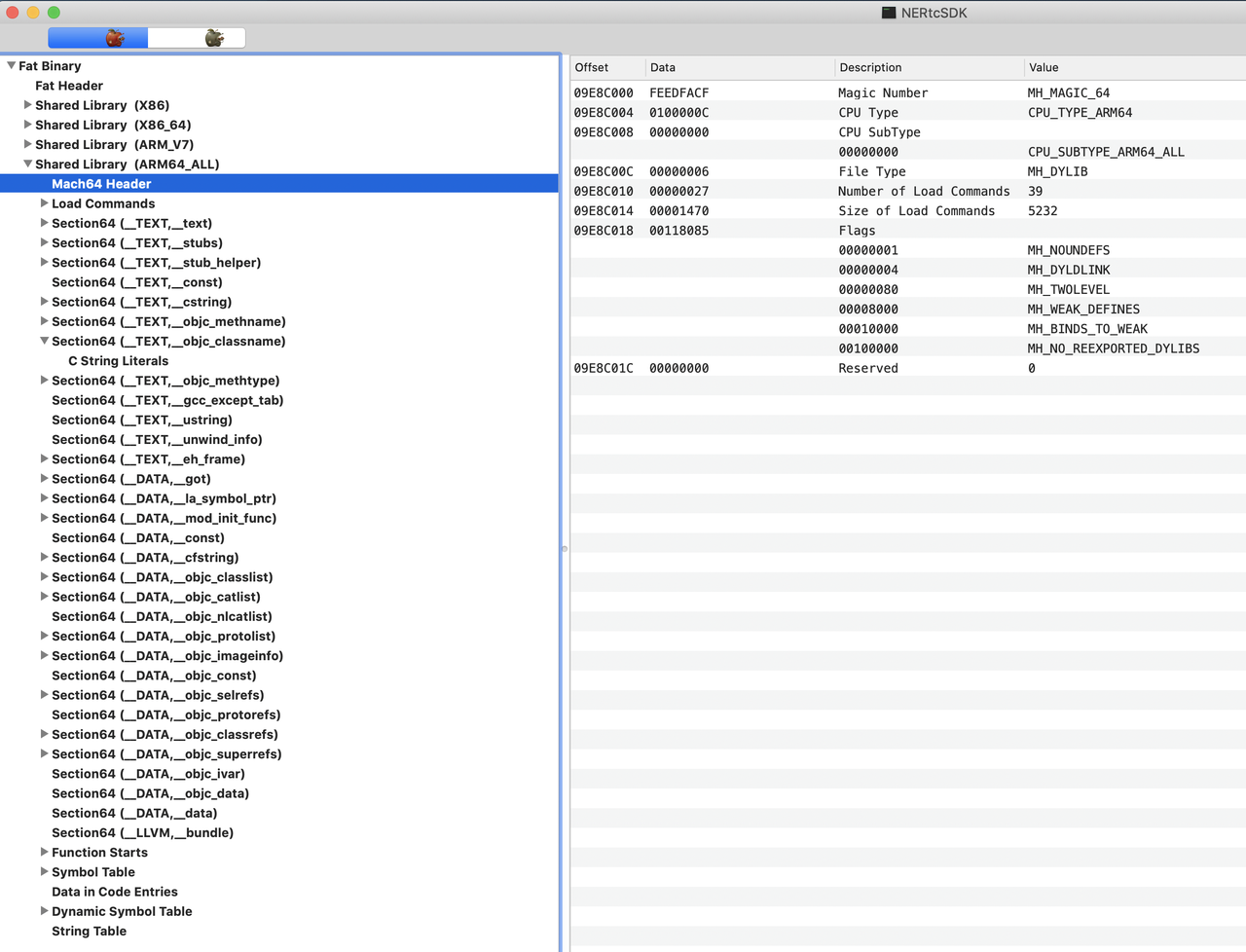
网上能找到很多Mach-O的struct解释,用简单通俗的语言来描述的话,一个可执行文件的运行,其中执行代码都是执行的汇编语句,每一句都写在了执行体文件内。
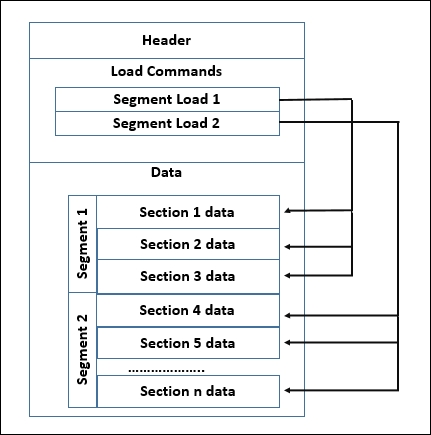
那么执行体肯定需要读取Mach-O,从头开始读取,必然要通过一定的数据结构找到下一执行语句的位置,一个类似树、或链表的结构。
于是Mach-O的总体数据结构如下:
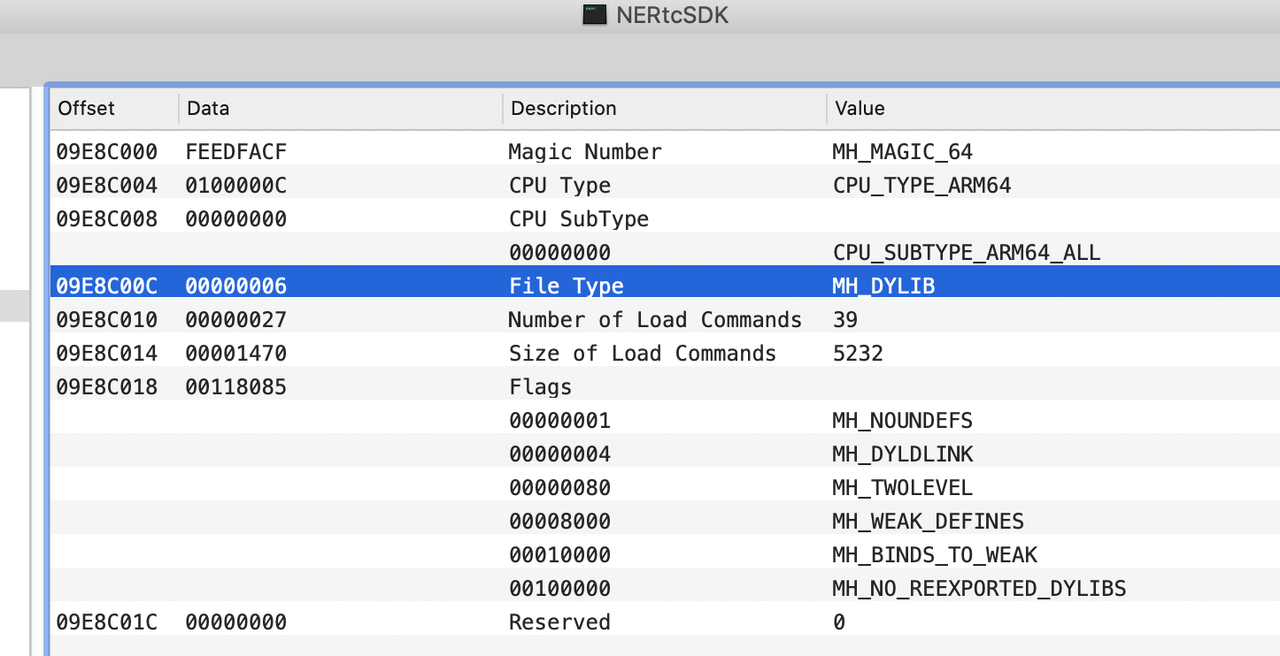
 因此通过下图,我们知道这个库的architecture是arm64,load命令总数有39个,size也确定了命令的读取范围,剩余的就进入了Section。
因此通过下图,我们知道这个库的architecture是arm64,load命令总数有39个,size也确定了命令的读取范围,剩余的就进入了Section。
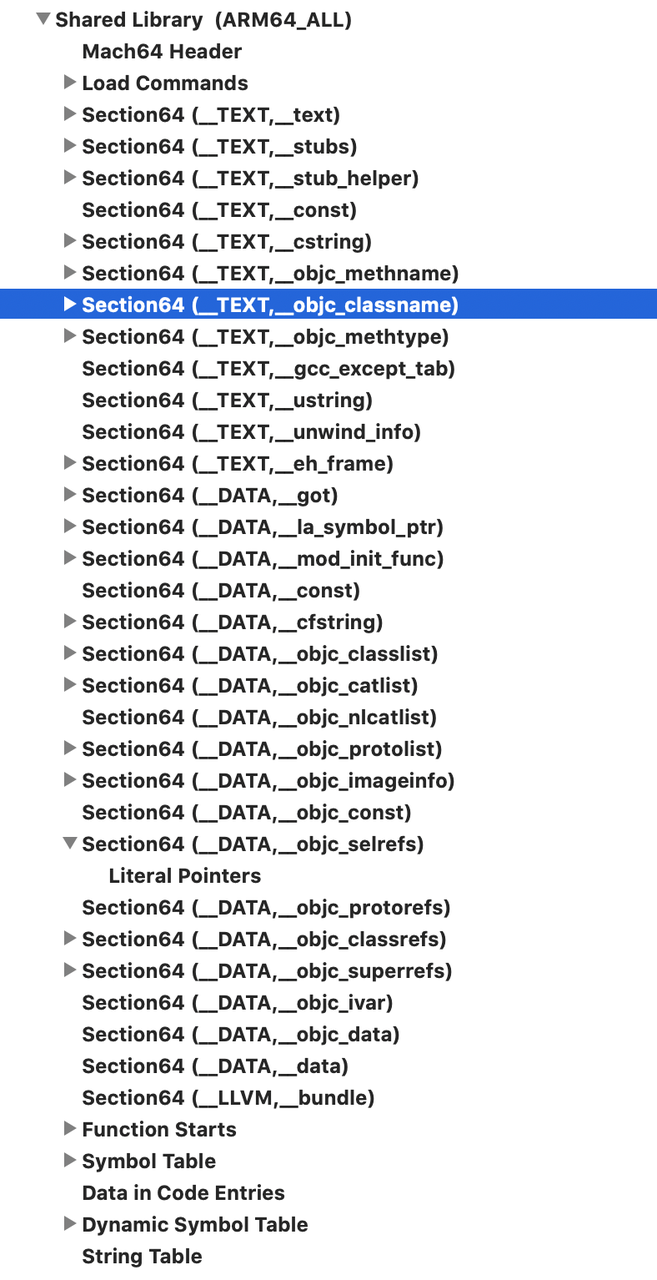
 那么Section数据就很多了,在这里我不一一列举。
那么Section数据就很多了,在这里我不一一列举。
值得一提的是,包体积优化,其实就是这些TEXT、DATA数据的体积优化,字符串越短、越少,包体积自然就小。
那么什么方法可以优化掉那么一长串的TEXT呢?
优化策略
1. 减少全局静态变量的使用,改为类对象
静态常量字符串是历来项目的重灾区,小小的字符串,日志打多了,可能会涨个几百KB。
2. 减少模版的使用
3. 避免重复代码、删掉无用代码
在删除之前,我们首先要弄清楚哪些代码会被编译成 *.o 文件打包进去,哪些不会。
下面就给几个常识性的错误来给大家演示一下:
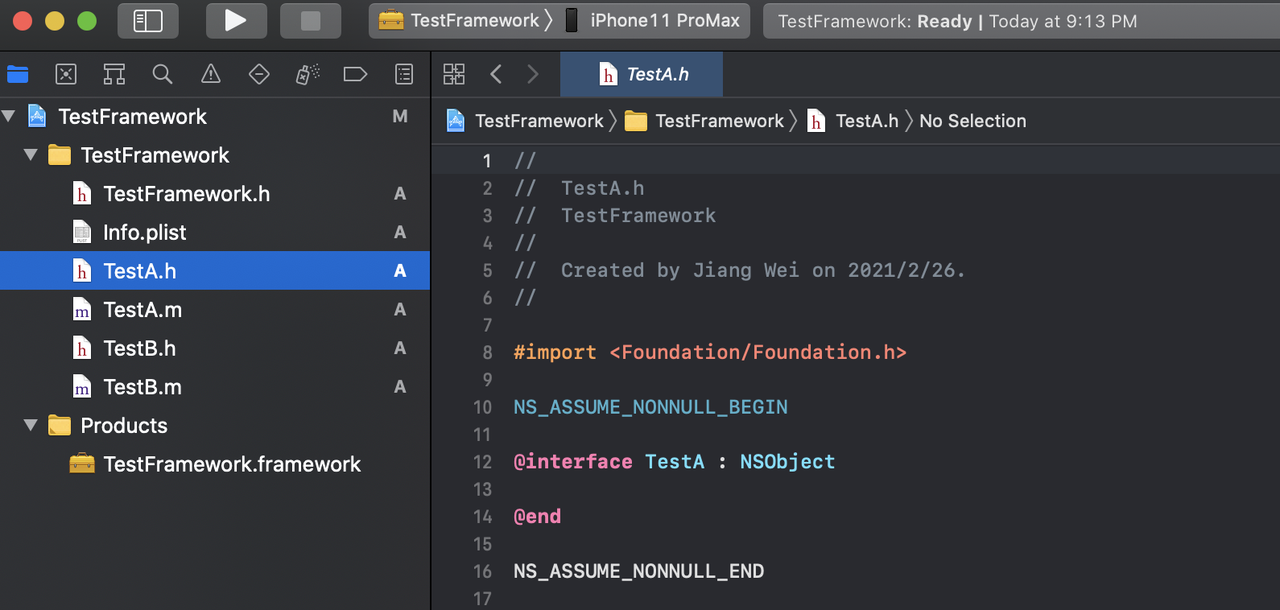
(1)如下TestFramework是一个动态链接库,对外没有暴露TestA, TestB,也没有文件引用他们。那么编译产出物会包含TestA, TestB吗?
(2)如下StaticLibrary是一个静态库,对外没有暴露TestA, TestB,也没有文件引用他们。那么编译产出物会包含TestA, TestB吗?
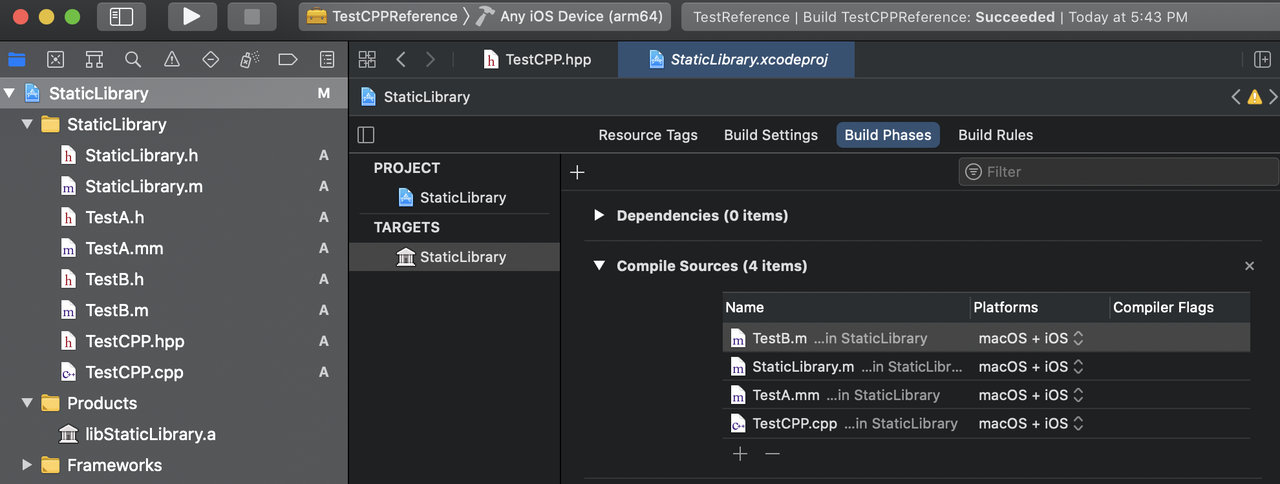
答案是:都会包含。
这一点我们当时实验的时候很诧异,工程里没有任何作用的代码,任我打开各种strip选项,编译器居然不会删掉无用代码symbol。
这里苹果TSI也给我们贴上了官方答复,原因就在于
”When linking a dynamic binary, all of the public entry points into that library must remain visible, since the compiler does not have any insight at the time the dylib is built what functions the consumer of the dylib needs, and this is not a feature that link time optimization provides. You can think of the dylib as read only after it is built, and is independent of the app containing it”
标准的动态库其实并不会有足够多信息知道哪些能被优化,哪些不能。因此这是第三方SDK供应商都必须要了解的一点。
因此仔细对比发现,Xcode只有嵌套引用的binary的无用代码才会被自动过滤掉,注意这一切都是自动的,并不受如上说的各种option控制。也就是说,只有子工程、依赖库的项目代码才具备link阶段优化的资格,主工程的源代码一概不清楚你到底用不用,统统给加进去了。
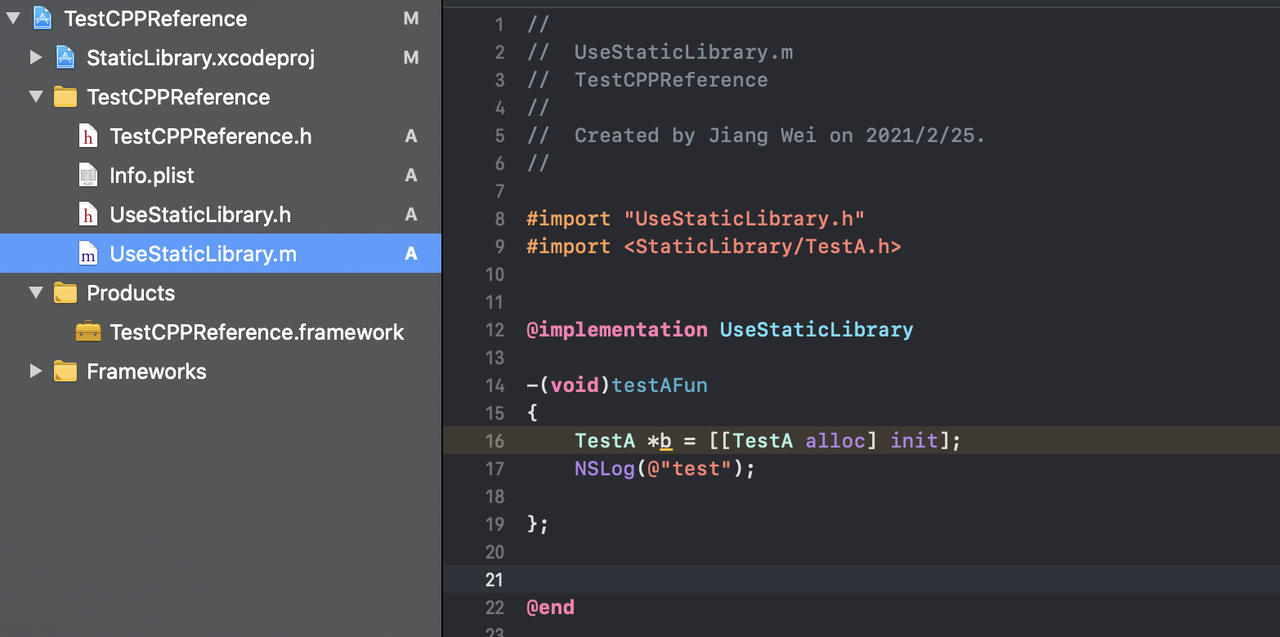
因此我做了一个列表,这些选项在何时以什么方式起作用
#Strip Linked Product
If enabled, the linked product of the build will be stripped of symbols when performing deployment postprocessing.
这个是总开关,打开了才会在deployment postprocessing中启用strip处理
#Deployment Postprocessing
If enabled, indicates that binaries should be stripped and file mode, owner, and group information should be set to standard values.
这个是strip只在deployment完成时候开始处理
#Strip Debug Symbols During Copy
Specifies whether binary files that are copied during the build, such as in a Copy Bundle Resources or Copy Files build phase, should be stripped of debugging symbols. It does not cause the linked product of a target to be stripped—use STRIP_INSTALLED_PRODUCT for that.
这个只有资源在Copy Files build phase有任务的时候才有意义,默认选YES即可。如果依赖的 Target 是独立签名的(比如 App Extension),strip 操作就会失效,并伴随着 Warning:warning: skipping copy phase strip, binary is code signed: xxxx。此情况将依赖的 Target 中的 Strip Linked Product 修改为 YES,保证依赖的 Target 是已经去除了符号即可,Waning 忽略掉就可以了。
#Strip Swift Symbols
Adjust the level of symbol stripping specified by the STRIP_STYLE setting so that when the linked product of the build is stripped, all Swift symbols will be removed.
开启 Strip Swift Symbols 能帮助我们移除相应 Target 中的所有的 Swift 符号,这个选项也是默认打开的。
#Optimization Level
Specifies the degree to which the generated code is optimized for speed and binary size. * None: Do not optimize. [-O0] With this setting, the compiler’s goal is to reduce the cost of compilation and to make debugging produce the expected results. Statements are independent—if you stop the program with a breakpoint between statements, you can then assign a new value to any variable or change the program counter to any other statement in the function and get exactly the results you would expect from the source code. * Fast: Optimizing compilation takes somewhat more time, and a lot more memory for a large function. [-O1] With this setting, the compiler tries to reduce code size and execution time, without performing any optimizations that take a great deal of compilation time. In Apple’s compiler, strict aliasing, block reordering, and inter-block scheduling are disabled by default when optimizing. * Faster: The compiler performs nearly all supported optimizations that do not involve a space-speed tradeoff. [-O2] With this setting, the compiler does not perform loop unrolling or function inlining, or register renaming. As compared to the Fast setting, this setting increases both compilation time and the performance of the generated code. * Fastest: Turns on all optimizations specified by the Faster setting and also turns on function inlining and register renaming options. This setting may result in a larger binary. [-O3] * Fastest, Smallest: Optimize for size. This setting enables all Faster optimizations that do not typically increase code size. It also performs further optimizations designed to reduce code size. [-Os] * Fastest, Aggressive Optimizations: This setting enables Fastest but also enables aggressive optimizations that may break strict standards compliance but should work well on well-behaved code. [-Ofast] * Smallest, Aggressive Size Optimizations: This setting enables additional size savings by isolating repetitive code patterns into a compiler generated function. [-Oz]
基本上大家Debug默认选择-O0,这样编译速度最快,Release只会选择-Os,这也是xcode默认选项。-Ofast只要代码写的足够规范,会进一步优化,但是还是侧重编译速度的。-Oz则是尽最大可能优化包体积,他可以优化编译器自动生成的重复代码。以云信为例,则选择-Oz。
Link-Time Optimization(LTO)
Enabling this setting allows optimization across file boundaries during linking. * No: Disabled. Do not use link-time optimization. * Monolithic Link-Time Optimization: This mode performs monolithic link-time optimization of binaries, combining all executable code into a single unit and running aggressive compiler optimizations. * Incremental Link-Time Optimization: This mode performs partitioned link-time optimization of binaries, inlining between compilation units and running aggressive compiler optimizations on each unit in parallel. This enables fast incremental builds and uses less memory than Monolithic LTO.
Debug依然建议选择No, Release建议选择全量Monolitic,这样优化的更加彻底。内存紧张的可以考虑Incremental。
#Dead code stripping
Activating this setting causes the -dead_strip flag to be passed to ld(1) via cc(1) to turn on dead code stripping.
值得一提的是,deadcode strip主要优化的是if 0这样子永远执行不到的代码块,并不是函数区。
#明白了Xcode的默认编译原理和编译选项,那我们的工作方针就很清楚了。
1. 去除一级项目中link的无效对象
因为Xcode天然只能不link二级项目、dependency的object,因此一级项目中的无效对象就处于无人处理的状态。
好在我们对Mach-O数据结构的了解到,所有ObjCClass是有个列表的,使用到ObjCClassRef也有一个列表的,通过对比class、classRef就可以轻松得知,什么类是无效类。
好在这样的事情,感谢已经有58的同仁邓立竹在做,经过交流这个工具很适合去除1级project的无效类代码,尤其是很多人在使用cocoapod的过程中,无意中带入的example代码类等等。
https://github.com/wuba/WBBlades
2. 子模块化工程架构
这需要对所有项目工程进行彻底的分解子模块化,这样得出来的好处不言而喻,那就是link工具可以细颗粒度的strip掉无效class代码,我们的代码重构工程显示SDK体积整整优化了30%,少了几十M。
3. 去除无人使用的函数
上面的几个优化重在优化掉无效类,那么进一步优化无用函数unused function则成了进一步优化的重点。
例如,很多项目里的加密功能,浩瀚的代码,其实也就使用其中一个函数而已,那么其他函数如何优化呢?
经过一番辛苦的翻阅资料,LTO进入了我的视野。
LTO(Link Time Optimization)是什么?
Link time optimization目的是希望在通过link阶段的优化达到编译出的文件体积更小、执行效率更高的一种优化方式。其实这个方案提出来执行在Gcc, LLVM Clang都适配,他们基本上均通过libLTO在bitcode埋点,在link阶段实现最终优化。
下图是armclang的一个官方解释,原理基本都是一样的。他们均通过-flto编译选项实现这个编译优化,最终在ld链接阶段还原到ELF executable的编译输出文件标准格式。
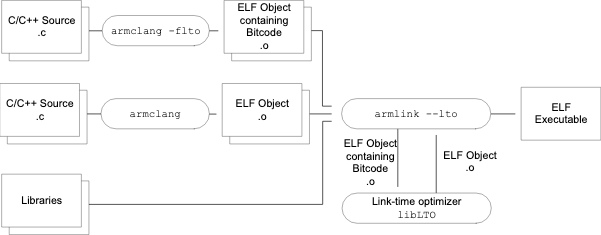
看懂了上图,也就明白了苹果多年前力推bitcode的苦心了。
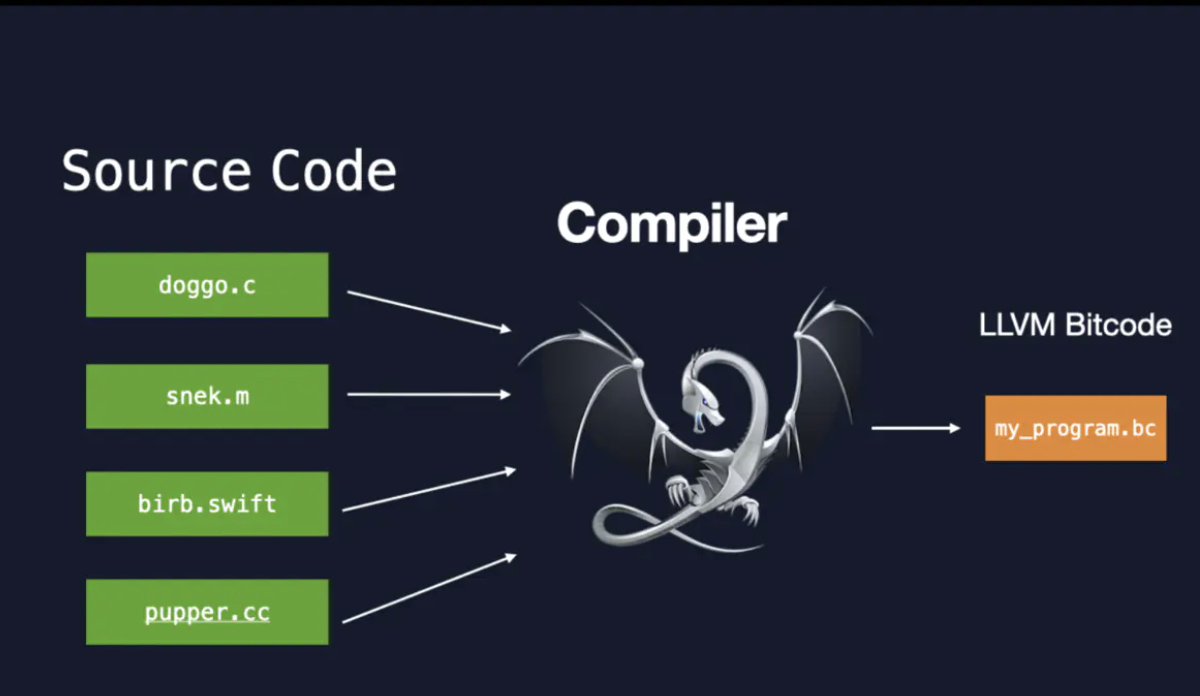
于是一番尝试后,我们基于iOS工程的LTO启用后,收到了意想不到的效果,SDK体积从285M降到266M。
然而我们并不满足于这点改进,我们继续深挖下去到WebRTC的海洋里试图寻找更多的优化空间。
一堆搜索后,我们发现WebRTC早在2004年就支持rtc_use_lto这个选项的。
它的编译体系是使用的gn,并且交由ninja实现了跨平台的编译。
然而不幸的是,2019年的WebRTC已经将其移除。具体的描述见链接,大意思是neon编译在特定的库编译不通过,因此禁用。
https://bugs.chromium.org/p/chromium/issues/detail?id=408997
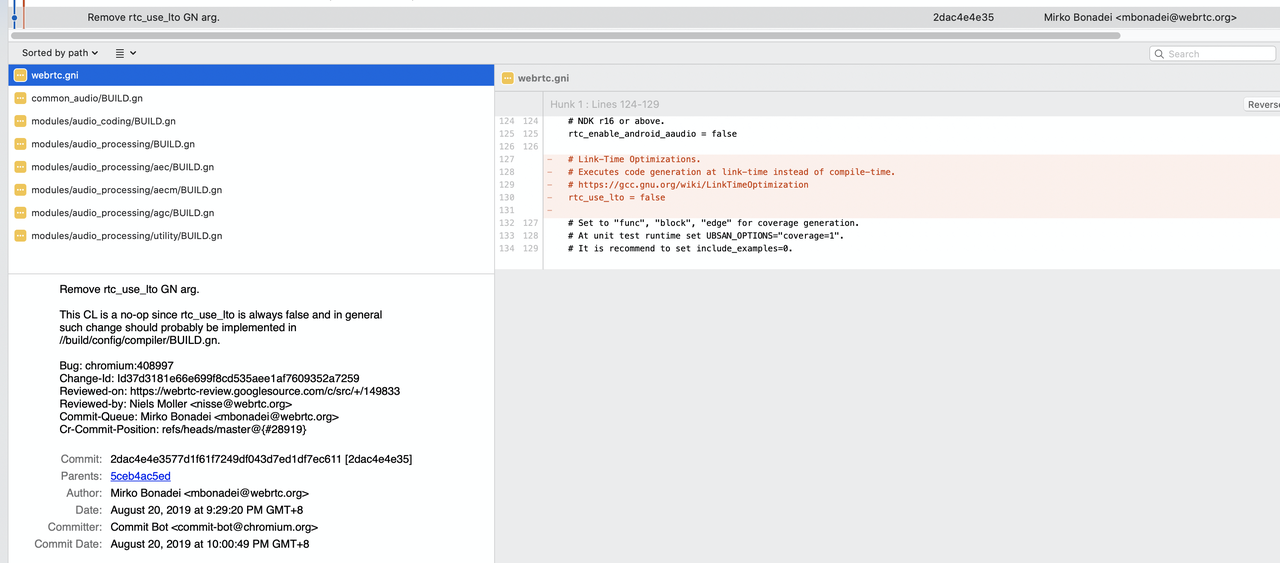
但是我们的场景其实用不到编译这个neon,因此我们又给加上了这个flag。
if (is_ios || is_mac) {
cflags = [ "-Oz" ] + common_optimize_on_cflags + ["-flto"]
#only enable Link time optimization for iOS/macOS as android already use --gc-sections
}
这一个神奇的flag加完了之后,iOS体积从280M降级到195M,整整共计优化了90M!!MacOS SDK也相应的从35MB降低到26MB。
同样类似的道理,我们在Android端编译层启用了-fdata-sections,-ffunction-sections并且在link阶段启用了–gc-sections,同样实现了巨量的体积优化。在这里我不再细说。
4. 常态监控流程
一次突击性的任务固然可以优化包体积很多,但是其中投入的人力精力是巨大的。
不如形成一个常态机制,定点监控包体积大小,分析模块所占的体积。
于是我们使用工具检测LinkedMap即可计算每个模块代码占据的体积 ,如图:
由此我们便可得知哪些模块消耗了多大的体积,根据判断做出优化。
总结
至此我们把竞品的Video视频SDK进行横向比较,均取最新版本,云信SDK完胜!
Twilio 276MB
Agora声网3.3 264MB
云信 4.2 195MB
包体积优化知识体系浩瀚复杂,在这条路上我们从最初的班门弄斧修改编译选项,到后来深入研究Mach-O存储格式原理,编译原理,才慢慢形成了一套方法论和监控维护体系。
云信目前的主要产品是客户端SDK,它是连接了亿万用户的输水管道,把SDK做到性能、体积优化极致是我们的最大的目标,未来我们也会持续总结优化方法,形成方法论和工具,让广大客户端、SDK公司产品也能得到受益。